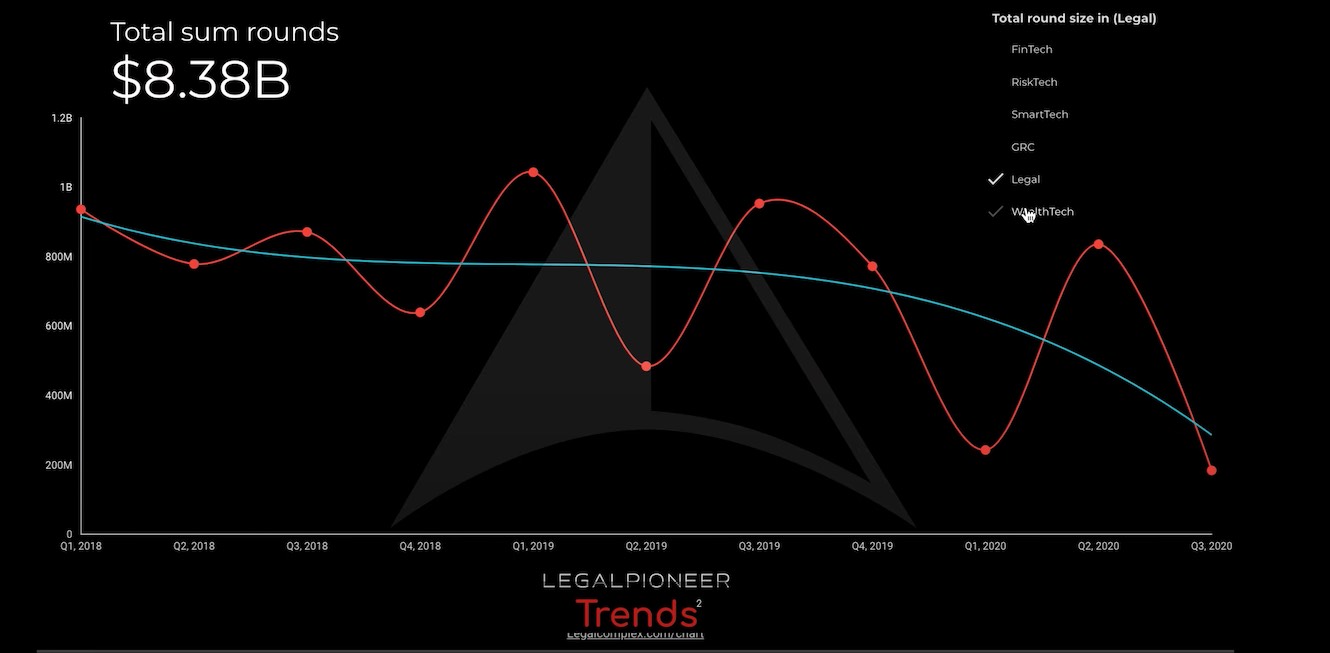
Will lawyers be replaced by GPT-3? Yes, and here’s when
Since legal data is monopolized, technologies like OpenAI’s GPT-3 can’t process legal queries. Here’s when this will happen.
Spoiler: We’ll pass legislation to democratize access to legal data. However, we need the legal industry to draft the law.
Backdrop
This essay was triggered by the many articles written by legal professionals quick to conclude: No, GPT-3 does not replace lawyers…yet. We can’t provide a timeline however we can explore the conditions when it will happen. The A.I. community offered a balanced view of the possibilities and pitfalls of GPT-3. For instance, it can’t do basic arithmetic at scale. Yet, GPT-3 has the ability to learn math from texts. So what happens when it learns the law? Once GPT-3 received a droplet of legal data, it came back with awesome.
Investor Michael Tefula primed GPT-3 to translate complicated legalese to plain English with only a couple of samples. There’s a cool video in the tweet where you see GPT-3 doing this in real-time. Ironically, his first instinct was to build an interpreter to replace lawyers. Is this possible?
According to Wikipedia: GPT-3 is trained on 410 billion tokens and has 175 billion parameters. Basically, GPT-3 learned how to predict the next word from reading lots of texts. As with math, GPT-3 can tackle a specific domain if it has enough data on that subject. A.I. won’t know how many eyes a six-legged purple unicorn has? But it does have data on a spider.
Legal Data
The legal industry operates on legal data. By design, legal data is data compiled by legal professionals to be decompiled by legal professionals. Here are the four main ways legal professionals generate legal data:
- Spot legal risks in non-legal documents or society at large;
- Find legal arguments in legal documents like legislation or case law;
- Construct and draft legal arguments like a contract or judgement;
- Explain legal arguments to a client or a judge.
All this can be replicated by a computer. The reason it hasn’t happen is that there is a shortage of accessible legal data to start the process. Why is there a shortage? Legal data sits behind multiple firewalls.
The first layer, just pierced by GPT-3 in the tweet above, is legal complexity. Unfortunately, that isn’t the only barrier. The second fence to block access to legal documents are privacy laws or copyright laws. The first is to prevent unauthorized use, the second to protect commercial interests. Besides virtual firewalls, we also have physical barriers. Usually, legal data is stored on-premise in silo’s and therefore isolated from the real world. A reason GPT-3 works this well is that it learns from reading domain data in context with real-world data.
Once legal data is liberated and connected, we could legitimately judge the impact of GPT-3. This shift to solely rely on tech won’t be a new experience for legal. The legal industry transitioned before when it was forced by courts to adopt eDiscovery: software trained to spot legal risks in massive sets of non-legal documents. Will it replace all legal work instantly? No, because unique or complex cases without prior data can still occur. However, as more data becomes available, these incidents themselves will become unique.
Here’s the best way I can frame this evolution: legal professionals are like traffic cops just before the roll-out of traffic lights. Not every cross-section has a traffic light, but it is harder to find a cop still directing traffic. Traffic lights need electricity and a bit of computing. With GPT-3, we have the computing. Now we just need the grid to come online. Here are the scenarios for how we’ll get there.
Universe One
We produce a law to open up legal data like legislation, government data, and anonymized case law to machines. Once the machines have processed the data, we’ll discover the biases in case law and the inconsistencies in legislation. During this transition period, society will struggle with their own biases before it can fix biases in our legal data. The breakthrough will come once humans surrender and prefer mathematical precision over human emotion. We’ll be smart enough to build a fail-safe and let the machine throw an exception in unique cases. We’ll enter the age of AutoLaw where machines guide us through conflicts the way traffic lights help us avoid collisions.
Universe Two
The world will realize that if we want a safe environment, we’ll need to treat everyone equally fair. What is fair is usually codified in constitutions and has a rich history. This should be taught at school as early as possible. Just like we teach math and coding to kids, we’ll need to feed them laws and regulations. This ensures we understand our rights and obligations when we’re young and practice it when we’re older. More minds on the law will also force improvements across the system. This will drive down the cost of legal education and subsequently the cost of legal representation. In short: no need to hire an $800 an hour lawyer when you can solve your own legal issues. In this universe, the reliance on experts in law will slowly expire.
Universe Three
What if we elect to go the opposite end? If we feel like the world is going too fast, we usually slam on the brakes. Instead of opening up legal data to machines and society, we pass laws to restrict access. Thereby effectively crippling any innovation in the legal space. Society won’t oppose it because collectively we feel comfort in keeping things unchanged. However, in a universe where data is scarce, we aren’t properly educated to make informed decisions. Bear in mind that limiting access to legal data protects a human monopoly on law and a pretty lucrative business model. Thereby making any justice crusade a costly endeavor. Setting in a downward spiral of unjust behaviors with an unpleasant end for all. I already have a law degree. I’ll be fine…for a while.
Bottom line
We often hear about the quality humans can provide in legal. Quality usually originating from ingenuity and not from consistency. Especially the ingenuity to unravel complex legal matter and explain it to laypeople. The process described in point 4 and the one GPT-3 just crushed on Twitter.
Like traffic lights help us avoid collisions, democratizing legal data will help us avoid conflicts. If we monopolize legal data, we make justice unattainable for all. And this principle goes against the very nature of why the legal industry exists.
Just remember, every time we’re dutifully reminded by legal professionals at every new technology breakthrough: lawyers still set the rules to access the law. The question is at what price?
The video below visualizes this post